Lakehouse Logic: Por que o armazenamento de objetos é o novo mecanismo de análise

A análise de dados se resume a um objetivo simples: fornecer às pessoas – e, cada vez mais, aos agentes de IA – a informação certa, no lugar certo, na hora certa.
É isso. É fácil de dizer. Mas historicamente difícil de alcançar.
A boa notícia é que o cenário está mudando. Com o surgimento das arquiteturas de data lakehouse, formatos de tabela abertos e a crescente importância dos metadados – especialmente na era do GenAI – o armazenamento de objetos está evoluindo para uma plataforma de alto desempenho para análises estruturadas.
Vamos explorar como chegamos aqui e por que essa mudança é importante.
De Data Warehouses e Data Lakes aos Lakehouses
Para entender o quanto a análise de dados evoluiu, considere que há apenas algumas décadas o processo de extração e transformação de dados e seu armazenamento em um data warehouse era, na melhor das hipóteses, demorado. Os usuários de negócios forneciam os requisitos e a expertise no domínio, mas o desenvolvimento de toda a solução, incluindo o design de relatórios e painéis, ficava a cargo do departamento de TI.
Em seguida, surgiu o BI de autoatendimento, permitindo que os usuários explorassem dados de forma independente – desde que estivessem disponíveis no armazém de dados. No entanto, ciclos de entrega lentos e esquemas rígidos frequentemente limitavam o acesso.
Combinado com avanços no processamento e armazenamento massivamente paralelo (MapReduce, Hadoop), o foco eventualmente se deslocou para os data lakes – ambientes escaláveis e flexíveis para armazenar grandes quantidades de dados brutos. Os dados se tornaram o novo petróleo e aqueles que os possuíam supostamente teriam uma vantagem competitiva. Mas a qualidade e a governança dos dados frequentemente ficavam para trás.
Mas, assim como o petróleo, que precisa ser refinado, as pessoas perceberam que, para fornecer valor, os dados precisavam ser transformados, limpos e catalogados. Os data lakes atenderam a essa necessidade ao combinar a flexibilidade dos data lakes com a integridade transacional e o desempenho dos data warehouses.
A vida à beira do lago parecia perfeita, mas não por muito tempo.
Chegou o Armazenamento de Objetos
Embora os data lakes fossem ótimos para armazenar dados estruturados e não estruturados, eles nem sempre eram ideais. Não é de se admirar que muitas vezes também fossem chamados de "pântanos de dados", já que o foco estava no volume e na variedade, mas nem sempre na qualidade dos dados.
Os armazenamentos de objetos simplificaram o gerenciamento de dados. Sua capacidade de armazenar objetos imutáveis os tornou ideais tanto para dados estruturados quanto não estruturados. Mas eles não eram perfeitos.
Desafios incluíram:
Para desbloquear todo o potencial do armazenamento de objetos, precisávamos de melhores capacidades de metadados, governança e consulta.
E agora chegou.
Apresentando Suporte Nativo para Tabelas S3 no VSP One Object
O VSP One Object da Hitachi Vantara leva o armazenamento de objetos a um novo patamar ao oferecer suporte nativo para Tabelas S3. Este é o primeiro do setor para armazenamentos de objetos locais. E as implicações são significativas.
Suporte nativo para Tabelas S3 significa:
Combinado com recursos integrados como um catálogo REST do Apache Iceberg, um mecanismo SQL sem configuração e um serviço de metadados avançado, o VSP One Object se torna uma base ainda mais poderosa para data lakehouse e cargas de trabalho de IA.
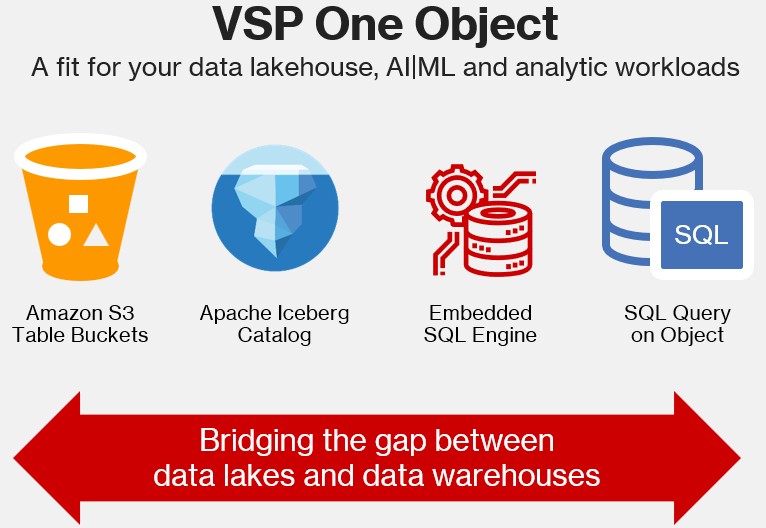
Desbloqueando Metadados S3 para Análises Mais Inteligentes
Além do suporte a tabelas, o VSP One Object introduz o registro de metadados S3. Quando ativado, cada evento de objeto – criação, atualização, exclusão – é registrado em um log imutável armazenado como uma Tabela S3.
Isso fornece funcionalidades críticas, incluindo:
Agora você pode gerenciar e analisar tanto seus dados quanto seus metadados usando as mesmas ferramentas – aumentando a governança, a observabilidade e o desempenho.
A Solução de Armazenamento de Objetos Certa no Momento Certo
As organizações estão sob pressão para fazer mais com seus dados do que nunca. E para fazer isso de forma mais rápida, inteligente e em maior escala. Quer você esteja construindo modelos de IA, habilitando análises em tempo real ou simplesmente tentando gerenciar um crescimento explosivo, a infraestrutura que você escolhe importa mais do que nunca.
O VSP One Object é projetado especificamente para este momento. Ele transforma o armazenamento de objetos tradicional em uma plataforma inteligente e de alto desempenho que suporta com facilidade as cargas de trabalho modernas de análise e IA.
É a solução certa no momento certo, proporcionando:
O VSP One Object é mais do que apenas armazenamento. É um facilitador estratégico para organizações que buscam liberar todo o potencial de seus dados – estruturados ou não, históricos ou em tempo real, gerados por humanos ou por máquinas.
Descubra mais sobre por que o GigaOm Radar para Armazenamento de Objetos reconheceu a Hitachi Vantara pela inovação em armazenamento de objetos ou conecte-se com seu representante da Hitachi Vantara para iniciar sua jornada de modernização de armazenamento de objetos.
Ler mais:



