First in a Series: Digital transformations are bigger data center challenges than we’d like to believe.
These projects fundamentally change an organization’s business processes, in part, by creating a chain reaction of new apps that require new types of infrastructure to live and breathe. In other words, to secure and deliver insights at the right speed, depends on the performance of the data center.
Two years ago, IDC said it expected that 500 million new digital apps and services would be built by 2023, which is more than all the applications built in the last 40 years. It should be noted that many of these new apps come with new workload types, in the form of compute vision, recommender systems, AI & ML, to name a few, and each with a completely different set of requirements compared to traditional IT workloads. In some cases, it is real-time access to data, and in other cases it is in combination with historical data across a group of applications.
A New World, A New App Requirement
After spending the last few decades building and managing data center solutions that were designed to deliver resiliency and performance to drive consistent and stable monolithic application services, we are now living in a new world. Today the application architecture is expanding to also incorporate new modern distributed apps, commonly referred to as cloud-native apps. Both types of architectures bring unique value to each other and will co-exist in the same data center. But they require distinctly different infrastructure components to perform optimally.
For example, block storage has traditionally been well suited for high throughput and high IO workloads, where low latency is important. Supporting workloads like Online Transaction Processing (OLTP) platforms, ERP systems, and traditional IT workloads with block storage always results in the best performance with highest resiliency.
However, with the advent of modern data workloads i.e., analytics workloads, such as AI and ML, traditional block-based platforms have been found lacking in their ability to meet the scale-out demand that the computational side of these platforms create. With such scale out architectures, storage capacity can be easily increased. And because there is more hardware to share the load, traffic capacity, such as, network connections, memory, and processing power, can also be easily increased. As a result, multiple compute nodes can connect as a single scale-out cluster, enabling workloads to run in parallel and expand with compute nodes as needed.
There are two approaches that can help bring such a process to life. The first is software-defined storage for block (scale-out) that features a native data plane to enable data to move seamlessly between scale-up and scale-out storage. A second solution is a scale-out file system that supports object-based storage.
The Storage Part of the Workload Strategy
Adopting the proper storage is as strategic as the advanced computational platform that organizations select. That’s because, underpowering a complex distributed computation platform will net lower performing results, diminishing the quality of the outcomes.
Rather, to support the computation platforms, it’s important to ensure that the storage technology utilized can meet the demands of the graphics processing unit (GPU) throughout the entirety of the data lifecycle. And don’t be fooled by claims of high throughput. Choosing a storage technology that can only support high throughput will net diminished results from the workloads that require very high IOPS, with low latency.
It is also important to utilise a storage technology that can meet the scale requirements of the data required to support the model training efforts. If the storage system can only support a single tier of storage medium, then it requires a data plane to move data between storage technologies.
Otherwise, AI platforms will suffer by not having access to the data they need at any given time. But utilising a platform that supports seamless integration between, for example, block scale-up and scale-out or the filesystem with integration to technologies like object storage, will net the greatest economical return. It will also reduce the labour necessary to maintain these systems and remove the brittle nature of traditional data movement or archiving engines.
Consider the Mission Critical
Imagine a scenario in which a business wants to apply an AI model on top of a mission-critical application to get high-speed recommendations. At a certain point in time there will be a need to separate data from the production environment to avoid latency impact and begin to utilize the benefit of extrema parallel read performance from a scale-out platform.
This is accomplished by moving block data to a scale-out platform that is hosting the AI model. In addition, these types of scale-out platforms can host new modern apps with extreme read performance thanks to some innovative patented tech, like the Hitachi Polyphase Erasure Coding.
The scenario is illustrated here by using a monolithic financial trading system in combination with new apps that use AI technology. The monolithic application retrieves information and orders and sells shares. The scale-out system can move data to a scale-out infrastructure where an AI model is applied to a copy of the production data. Via high-speed processing, a recommendation is delivered back to the trading system.
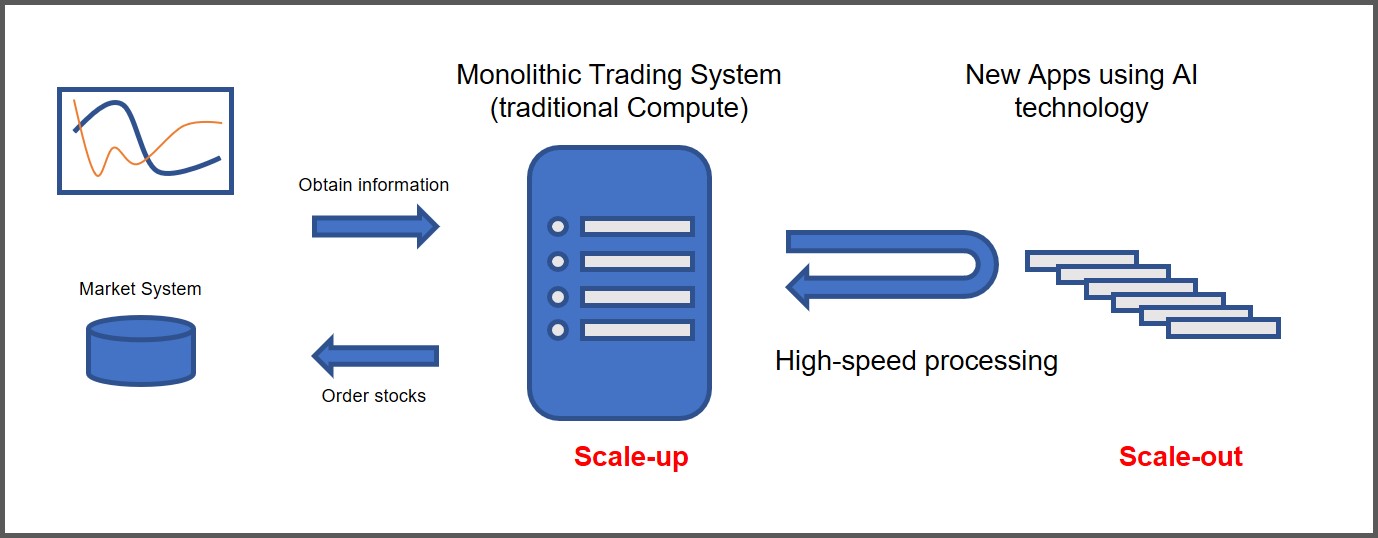
This simplified example shows a way in which realization of real-time trades can take into account multiple financial products and complex trading rules. The scale-up and scale-out technology can expand business applications that require an optimal combination of near-real-time operation with high-speed processing.
Hitachi Vantara, with its combination of Hitachi Enterprise VSP and Hitachi Software Defined storage, can address these problems and more. From Enterprise VSP scale-up storage with highest resiliency, availability, and performance to move data via a data plane to Hitachi Software-Defined Storage (scale-out) platform with ultra-high parallel read performance.
This is the first in a series on the impact of the changing workload on the data center. The next story will focus on the 5 new workloads changing the landscape, while a third will discuss an interesting scale-out option that connects file system storage to object-based storage. Stay tuned!
Related
 Tom Christensen
Tom Christensen






