How Data Agility Fuels Growth for Financial Services

Data paves the way for every strategic move made by banks and insurance companies. Whether looking to create a new service, complying with regulations, or overhauling and re-engineering legacy operations, a massive data project is always central to the effort. For financial services businesses, the pace at which they can reshape and repurpose data has become a key determinant of their ability to predict market trends and meet client expectations.
The newcomers in the finance industry are digital natives. Data agility is part of their DNA. These firms were founded on agile and responsive data supply chains, which themselves are frequently based on DataOps principles. They are unburdened by legacy data warehouses and data lakes based on technology built for the requirements of past eras.
For established players, requests for the data needed to support advanced analytics, artificial intelligence (AI) and machine learning (ML) projects, research and, ultimately, the development of innovative new products often take far too long to fulfill. This severely restricts the ability of these institutions to grow. The most effective solution is to immediately, if not gradually, move toward creating an agile data infrastructure. Sometimes called a data fabric, this approach affordably supports creating and maintaining the huge number of data pipelines needed to compete in today’s financial services marketplace.
The forces driving the finance industry toward agile data are rooted in the twin demands for instantaneous knowledge and the anticipation of constant change. Hyper-personalization, data-led listening and real-time everything are the new normal for financial services.
The customers for financial services have come to expect the instant satisfaction provided by the excellent experiences they enjoy from digital consumer businesses such as Amazon, Netflix, Uber and smaller boutique brands. Whether a person is making a payment, sending money across borders, or anticipating market data for an investment decision, anything slower than “right now” is inherently frustrating. That is the standard against which financial services are being judged. Slow processes are the visible reflections of cumbersome systems that are incapable of meeting modern requirements.
Elon Musk famously said, “all user input is error,” when he explained the rationale for removing turn signals and even steering wheels from Tesla vehicles. His point was that sensors and software have the capacity to exceed human decision-making and reaction in many application settings. Thanks to the increasing use of AI to drive customer journeys, systems used in financial services are often expected to anticipate needs and decisions. All this helps drive the need to provide customers with a deeply personalized, highly automated experience capable of constantly advising them and steering them toward their individual, specific financial goals.
Financial services firms are masters of data capture, creation and storage, techniques essential for storing product information, capturing customer details, processing transactions and keeping records of accounts. However, that data platform, the bedrock of most financial institutions, was not built for a real-time world that must feed huge rivers to data analytics and AI or ML apps.
It is no longer sufficient to securely store data and make it retrievable by only a very narrow, controlled set of applications and business intelligence (BI) tools while operating at the languorous pace of batch processing. The data infrastructure is either static and fragmented across data silos or stuck on legacy platforms incompatible with today’s requirements. Both scenarios result in impedance mismatches between products and underlying data and ultimately between expectations and deliverables.
The current infrastructure can deliver some data in real time when needed, but enabling that capability requires far too much work. The same is true for creating, deploying and operating advanced analytics and AI or ML models. Minor changes meant to enhance customer journeys and keep pace with expectations require major development work, which compromises the agility and competitiveness of digital products and services.
The way forward is to adapt the current data platform to one in which support for real-time delivery and rapid change is built in. An agile data platform does this by bringing to life the support for rapid change and stable operations that DataOps supports.
An agile data platform is built on three layers that support the transition from legacy infrastructure to an agile data-driven environment:
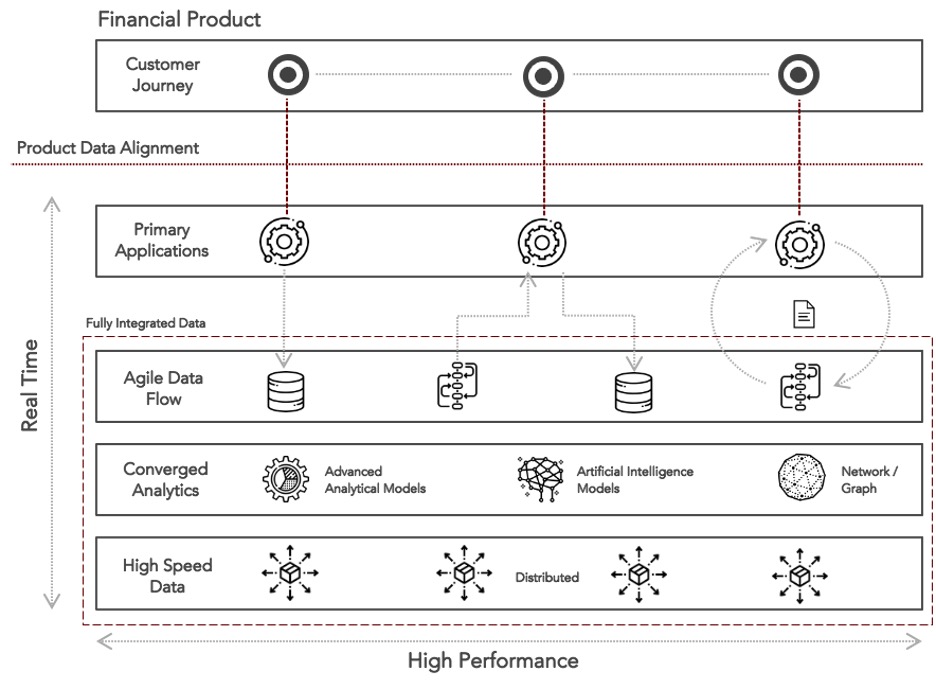
Figure 1: An Agile Data Platform
Adopting the foundational layers shown in Figure 1 to power modern experiences and meet business requirements will be challenging, but such an effort will be the minimum required to remain competitive. The potential rewards, however, are substantial. Here are just a few use cases that reflect both new and enhanced products, as well as operational modernizations made possible:
The pain of adapting data to meet the needs of new applications and the rising cost of supporting bespoke solutions on legacy data infrastructure will drive companies inexorably toward agile data platforms. Just like early adopters of agile and DevOps realized, the benefit of creating an agile data platform based on DataOps will be accelerated innovation that competitors will not be able to match.



